AWS Copilot CLI로 배포하던 프로덕션 서버를 AWS CDK로 마이그레이션하기
AWS Copilot CLI로 운영하던 ECS Fargate 기반 프로덕션 서버를 AWS CDK로 옮기며, 왜 옮겼고 무엇을 먼저 확인했으며 어떤 순서로 위험을 줄였는지 정리했습니다.

On this page
처음 팀 배포 워크플로우를 세팅할 때 AWS Copilot CLI를 썼다.
Dockerfile이 있고, 서버는 컨테이너로 띄우면 되고, 로드밸런서와 ECS Fargate와 로그와 배포 파이프라인을 매번 하나씩 조립하고 싶지는 않았다. 그럴 때 Copilot은 좋은 선택이었다. copilot init, copilot env deploy, copilot svc deploy 같은 명령어 몇 번이면 “프로덕션에 올릴 수 있는” 모양이 금방 나왔다.
무엇보다 실제로 편했다. 특히 manifest.yml로 인프라 설정을 제어할 수 있는 점이 좋았다.
CPU, memory, count, health check, environment, domain 같은 설정을 YAML로 읽고 고칠 수 있었다. 내부적으로는 CloudFormation stack이 만들어지고, 그 아래에는 VPC, ALB, Target Group, ECS Service, Task Definition, IAM Role, CloudWatch Log Group 같은 리소스가 생긴다. 하지만 매번 그 리소스를 하나씩 직접 조립하지 않아도 된다는 점이 Copilot의 장점이었다.
시간이 지나면서 아쉬운 점은 생겼다. 어느 순간부터 배포가 조금 느려졌고, 가끔 배포 장애도 있었다. 그래도 당장 뒤엎을 만큼 심각하진 않았다. 이미 팀이 배포하는 방식 안에서 잘 굴러가고 있었고, YAML로 인프라를 제어하는 방식도 충분히 만족스러웠다.
마이그레이션의 계기는 지원 종료 공지였다.
AWS가 2026년 6월 12일자로 Copilot CLI 지원을 종료한다고 공지했다. 오픈소스 프로젝트로는 계속 남지만, AWS가 새 기능이나 보안 업데이트를 제공하지 않는다면 프로덕션 배포의 중심에 계속 두기는 애매했다.
그래서 이번에는 Copilot CLI로 배포하던 프로덕션 서버를 AWS CDK 기반으로 옮겼다.
배포 명령어만 바꾸는 수준을 넘어, 서버를 둘러싼 인프라의 소유권을 Copilot manifest에서 CDK 코드로 옮기는 일이었다.
참고로 본문에 나오는 계정 ID, 도메인, repository, stack 이름은 실제 값 대신 예시로 바꿔 적었다.

왜 지금 옮겨야 했나
나는 처음에 이렇게 생각했다.
“지원 종료되는 Copilot CLI를 계속 프로덕션 배포 경로에 둬도 되나?”
먼저 구분해야 할 것이 있었다.
지원 종료가 곧 서버 중단을 뜻하지는 않는다. Copilot이 만든 리소스는 CloudFormation, ECS, ALB, IAM, CloudWatch 같은 AWS 리소스다. 그리고 Copilot CLI 자체도 오픈소스 프로젝트로 남는다.
그래서 “당장 장애가 나니까 옮겨야 한다”는 아니지만, 다만 내 상황에서는 옮기는 쪽으로 기울었다. 이유는 세 가지였다.
첫 번째, 이 글을 쓰는 2026년 6월 11일 기준으로 AWS는 Copilot CLI가 2026년 6월 12일에 지원 종료된다고 공지했다. AWS 공식 공지는 Copilot이 계속 GitHub에 남더라도 AWS의 새 기능이나 보안 업데이트는 더 이상 받지 않는다고 설명한다.
두 번째, AWS도 같은 공지에서 기존 Copilot 애플리케이션을 ECS Express Mode나 CDK로 옮기는 경로를 안내했다. AWS가 이미 선택지를 제시한 상태였다.
세 번째, 어차피 마이그레이션을 해야 한다면 이번 기회에 운영 환경변수와 시크릿, GitHub Actions 배포 절차, ECS task definition을 더 명시적으로 정리하고 싶었다.
결론은 단순했다. 잘 쓰던 도구의 지원이 끝나니, 프로덕션 배포 경로를 지원되는 방식으로 옮기는 게 맞다고 판단했다.
그래도 다른 길을 확인해보기
그렇게 정리하고 나서도, 진짜 CDK로 옮기는 게 맞는지 한 번 더 확인했다.
선택지는 다시 세 가지였다.
첫 번째는 그냥 Copilot을 계속 쓰는 것.
가능은 하다. 이미 잘 돌아가고 있었고, 당장 서버가 멈추지도 않는다. 가장 비용이 낮은 선택지이기도 하다. 다만 지원 종료 이후에는 새 기능과 보안 업데이트를 AWS에서 기대하기 어렵다. 프로덕션 배포 경로에 그 상태의 CLI를 계속 두는 것이 마음에 걸렸다.
두 번째는 Copilot이 만든 CloudFormation 템플릿을 계속 들고 가는 것.
Copilot은 내부적으로 CloudFormation 스택을 만든다. copilot svc package를 쓰면 서비스 배포에 사용되는 CloudFormation 템플릿을 뽑아볼 수도 있다. 즉, Copilot 없이도 생성된 템플릿을 이해하고 이어받는 방식이 가능하다.
하지만 나는 이 선택지는 끌리지 않았다. Copilot의 manifest.yml은 쓰기 편했지만, 생성된 CloudFormation YAML을 직접 관리하는 것은 다른 이야기다. Copilot의 간편함은 사라지고, CDK의 타입과 추상화도 얻지 못한다. “중간 상태”에 오래 머무는 느낌이었다.
세 번째는 CDK로 새 stack을 만들고, 기능 단위로 검증한 뒤 트래픽을 옮기는 것.
가장 귀찮지만 가장 이해하기 쉬운 방식이었다. 기존 Copilot 스택을 억지로 뜯어고치는 대신, CDK로 같은 역할을 하는 인프라를 만들고, 새 ECS 서비스가 정상 동작하는지 확인한 뒤, DNS나 로드밸런서 경로를 바꾸는 식이다.
이 검토까지 하고 나니 새 CDK stack을 병렬로 만드는 쪽이 더 분명해졌다. 프로덕션 마이그레이션에서는 되돌릴 수 있어야 한다.
Load Balanced Web Service의 대체 방식 고르기
그다음에는 더 구체적인 질문이 남았다.
지금 Copilot으로 배포하는 서버는 어떤 유형이고, AWS가 제안한 대체 방식 중 무엇으로 옮겨야 할까?
서버는 Copilot의 Load Balanced Web Service 케이스였다. repo 기준으로 copilot/app/manifest.yml의 type이 Load Balanced Web Service였고, ALB 뒤에서 동작하는 ECS Fargate API 서버였다. 이 판단을 하던 2026년 6월 11일은 Copilot CLI 지원 종료일인 2026년 6월 12일의 하루 전이었다.
기준을 하나로 잡기 어려웠다. 단순히 새 public API를 빠르게 띄우는 문제라면 ECS Express Mode도 충분히 매력적이다. 하지만 나는 기존 운영 구성을 최대한 보존해야 했다. AWS 기본값에 많이 맡기는 방식만으로는 세부 설정을 맞추기 어려워 보였고, 손이 더 가더라도 CDK로 현재 Copilot 구성을 직접 옮기는 쪽이 낫다고 봤다.
대안은 이렇게 정리했다.
| 대안 | 맞는 상황 | 이번 글에서의 처리 |
|---|---|---|
| ECS Express Mode | 새 public API를 빠르게 띄우고 AWS 기본값을 받아들일 수 있을 때 | 기존 운영 설정을 맞추기 어려워 제외 |
CDK ApplicationLoadBalancedFargateService | Copilot Load Balanced Web Service를 CDK로 옮길 때 | 여기서 시작 |
| CDK 하위 ECS/ALB construct 직접 구성 | L3 construct로 맞추기 어려운 설정이 있을 때 | 필요한 부분만 내려가기 |
| 기존 Copilot 계속 사용 | 시간이 너무 부족해 임시로 버텨야 할 때 | 장기 경로에서는 제외 |
이 코드베이스에는 CDK가 더 맞았다. 현재 Copilot 설정이 단순히 “컨테이너 하나 띄우기” 수준에 머물러 있지 않았기 때문이다.
- public ALB service
- custom ACM 인증서
/healthhealth check- container port
3000 - autoscaling
1-3 - CPU, request, response time 기반 scaling 설정
- Service Connect enabled
- SSM Parameter Store 기반
SENTRY_RELEASE - GitHub Actions에서
copilot secret init,copilot svc deploy사용
그래서 방향을 이렇게 잡았다. 처음에는 CDK의 ApplicationLoadBalancedFargateService로 시작하고, 부족한 부분이 나오면 하위 ECS/ALB construct로 내려간다. 새 서비스를 처음 띄우는 상황이라면 Express Mode도 괜찮았겠지만, 이미 운영 중인 Copilot 서비스를 옮기기에는 제어권이 부족할 가능성이 컸다.
이 판단은 뒤의 secret 이관 문제와도 이어졌다. 기존 workflow는 .env.prod를 .env로 바꾼 뒤 Docker image를 만들고 있었다. CDK로 옮긴다면 이 부분도 같이 끊고, SSM Parameter Store나 Secrets Manager에서 runtime에 주입하는 쪽으로 바꾸는 게 맞았다.
먼저 Copilot이 무엇을 만들었는지 보기
바로 CDK 코드를 짜기 전에 Copilot이 만든 리소스를 먼저 펼쳐봤다.
copilot app ls
copilot env ls
copilot svc ls --app <app-name>
copilot svc show --app <app-name> --name <service-name> --json
copilot svc package -n <service-name> -e <env-name> --output-dir ./infrastructure여기서 보고 싶었던 것은 운영 계약이었다.
- 어떤 VPC와 Subnet에 올라가 있는가
- ECS Cluster와 Service 이름은 무엇인가
- Task CPU, Memory, desired count는 얼마인가
- 컨테이너 포트와 health check path는 무엇인가
- ALB가 public인지 internal인지
- Security Group inbound/outbound 규칙은 무엇인가
- 환경 변수와 Secret은 어디서 오는가
- 로그 그룹 이름과 retention은 어떻게 되어 있는가
- Auto Scaling 기준은 CPU인지 Memory인지 Request count인지
- 도메인과 인증서는 어디에 붙어 있는가
이걸 하지 않고 CDK부터 짜면 위험하다…
“대충 Fargate 서비스 하나 만들면 되겠지”라고 생각하기 쉽지만, 프로덕션 서버는 대충 뜨는 것과 똑같이 동작하는 것이 다르다. 특히 health check, grace period, secret 주입, security group, task role 권한 같은 것은 빠뜨려도 배포는 성공할 수 있다. 그리고 나중에 이상한 곳에서 터진다! (나도 알고 싶지 않았다…)
다만 목표를 Copilot 리소스의 1:1 복제에 두지는 않았다.
반드시 맞춰야 하는 것은 사용자와 운영에 영향을 주는 계약이었다. 컨테이너 이미지와 포트, 환경 변수와 Secret, health check path, CPU와 Memory, desired count, public/private 접근 방식, task role 권한, 외부 도메인이 여기에 들어갔다.

CDK로 옮긴다는 것
AWS CDK는 인프라를 TypeScript, Python, Java, Go 같은 일반 프로그래밍 언어로 정의하고, 그 결과를 CloudFormation을 통해 배포한다. 결국 배포 엔진은 CloudFormation이다. 사람이 CloudFormation YAML을 직접 쓰지 않고, 코드로 stack과 construct를 조립한다.
솔직히 말하면, 처음부터 “CDK가 훨씬 낫다”고 체감하지는 못했다.
오히려 추상화만 놓고 보면 Copilot manifest가 훨씬 편하다. 누구나 봐도 그렇다.
Copilot manifest에서는 이렇게 사용한다.
type: Load Balanced Web Service
cpu: 512
memory: 1024
count: 2
http:
path: "/"짧고 좋다.
이 몇 줄이면 “로드밸런서가 붙은 ECS 서비스”라는 의도가 바로 드러난다. 초기 팀에서 배포 워크플로우를 빠르게 만들고 운영하기에는 이 추상화가 정말 좋았다.
반면 CDK에서는 같은 일을 훨씬 길게 쓴다.
const service = new ecsPatterns.ApplicationLoadBalancedFargateService(
this,
"ApiService",
{
cluster,
desiredCount: 2,
cpu: 512,
memoryLimitMiB: 1024,
publicLoadBalancer: true,
taskImageOptions: {
image: ecs.ContainerImage.fromEcrRepository(repository, imageTag),
containerPort: 3000,
environment: {
NODE_ENV: "production",
},
secrets: {
DATABASE_URL: ecs.Secret.fromSecretsManager(databaseUrlSecret),
},
logDriver: ecs.LogDrivers.awsLogs({
streamPrefix: "api",
logRetention: logs.RetentionDays.ONE_MONTH,
}),
},
},
);
service.targetGroup.configureHealthCheck({
path: "/health",
healthyHttpCodes: "200",
});Copilot manifest와 놓고 보면, 이 코드는 길고 알아야 할 것도 많다. cluster, task image option, log driver, secret source, target group health check처럼 Copilot이 감춰주던 세부 설정을 직접 만지게 된다.
일반적으로 IaC의 장점은 분명하다. 변경을 코드 리뷰할 수 있고, diff를 볼 수 있고, 같은 인프라를 재현할 수 있다. 하지만 이번 마이그레이션을 하는 동안에는 그런 장점이 크게 와닿지 않았다. 당장 든 생각은 “아, 이제 내가 더 많이 알아야 하는구나”였다.
결정한 트레이드오프들
첫 번째: 기존 리소스를 가져올까, 새로 만들까
마이그레이션을 시작하면서 처음 부딪힌 선택지는 “기존 Copilot 리소스를 CDK가 이어받게 만들 것인가, 아니면 새 CDK stack을 병렬로 만들 것인가”였다.
처음에는 기존 Copilot 리소스를 CDK로 adopt하는 방식도 생각했다. 이미 떠 있는 VPC, ALB, ECS Cluster, Service를 그대로 이어받으면 일시적인 중복 비용이 거의 없다. 겉으로는 가장 깔끔하다.
그런데 운영 관점에서는 별로 깔끔하지 않았다.
Copilot이 만든 CloudFormation stack이 이미 리소스를 소유하고 있는데, CDK가 같은 리소스를 다시 소유하려고 하면 경계가 애매해진다. “이 리소스는 누가 업데이트하는가?”라는 질문이 생긴다. 더 무서운 건 rollback이다. adopt 도중 상태가 꼬이면 Copilot으로도, CDK로도 자신 있게 되돌리기 어려워질 수 있다.
결국 새 CDK stack을 병렬로 만드는 쪽을 골랐다. 프로덕션 마이그레이션에서는 되돌릴 수 있어야 했다.
일시적으로 비용은 조금 더 든다. ALB 같은 리소스가 잠깐 중복될 수 있다. 하지만 새 서버를 충분히 검증한 뒤 트래픽을 넘길 수 있고, 문제가 생기면 기존 Copilot stack으로 돌아가면 된다. 프로덕션 마이그레이션에서는 이 단순한 rollback 가능성이 생각보다 큰 보험이다.
두 번째: 기존 VPC를 쓸까, 새 VPC를 만들까
새 CDK stack을 병렬로 만들기로 정하고 나니 다음 질문이 나왔다.
CDK stack은 새로 만들되, 기존 VPC와 subnet은 import해서 쓸 것인가? 아니면 VPC까지 완전히 새로 만들 것인가?
이 선택도 꽤 중요했다. ECS Service와 ALB만 떼어놓고 보면 새 VPC를 만들어도 될 것 같다. 하지만 프로덕션 서버는 보통 혼자 떠 있지 않다. DB, Valkey, SQS, Lambda, 내부 API, route table, VPC endpoint, security group 같은 네트워크 가정 위에 올라가 있다.
여기서 VPC까지 새로 만들면 격리는 좋아진다. 그만큼 기존에 맞춰둔 RDS 접근, security group rule, route table, egress, private subnet 구성을 다시 맞춰야 한다. 이 경우에는 서버 자체보다 네트워크 재구성이 더 큰 리스크가 된다.
그래서 기존 VPC와 subnet을 CDK에서 import해서 쓰는 쪽을 골랐다. 네트워크 격리를 위해 새 VPC를 만들 수도 있었지만, 그 선택은 DB 연결과 security group을 다시 맞추는 일까지 함께 끌고 온다.
이렇게 하면 병렬 배포의 장점은 유지된다. 기존 Copilot ECS와 ALB는 그대로 두고, 같은 VPC 안에 새 CDK ECS와 ALB를 띄워 검증할 수 있다. 동시에 DB나 Valkey 같은 기존 리소스가 기대하는 네트워크 조건을 크게 흔들지 않는다.

물론 기존 VPC를 import한다고 모든 게 자동으로 해결되지는 않는다. 새 ECS Service의 security group이 DB security group에 접근할 수 있어야 하고, 외부로 나가는 경로나 VPC endpoint가 필요하다면 그것도 확인해야 한다. 그래도 네트워크를 통째로 새로 만들 때와 비교하면 확인할 변수가 훨씬 적었다.
그래서 새 인프라를 만들면서도 기존 네트워크 조건은 유지하는 쪽을 택했다.
세 번째: Service Connect는 이번 범위에서 빼기
다음으로 본 것은 Service Connect였다.
Copilot으로 만든 ECS 서비스에는 Service Connect 설정이 붙어 있었다. 이 기능 자체는 좋다. ECS 서비스끼리 내부 DNS 이름으로 통신할 수 있게 해주고, 서비스 디스커버리와 연결 관리를 조금 더 편하게 만든다.
다만 이번 마이그레이션에서는 필수 조건이 아니었다.
현재 ECS 서비스는 1개였고, 다른 ECS 서비스가 내부 DNS 이름으로 이 서비스를 호출하는 코드 경로도 없었다. 외부 트래픽은 ALB를 통해 들어오고, 내부 의존성은 DB, Valkey, SQS, Lambda 쪽에 몰려 있었다.
그래서 새 CDK stack에서는 Service Connect를 끄고 시작했다. 기존 Copilot service가 쓰던 namespace와 alias를 새 서비스가 같이 건드리면, 내부 이름 충돌 같은 불필요한 변수가 생길 수 있었다.
나중에 ECS 서비스가 여러 개로 늘어나고 내부 호출 계약이 생기면 그때 Service Connect를 다시 켜면 된다. 그때는 새 namespace를 만들지, 기존 namespace를 정리해서 쓸지 별도 의사결정으로 다루는 편이 낫다.
네 번째: 미뤄뒀던 환경변수와 시크릿 정리하기
다음으로 손본 것은 환경변수와 시크릿 처리 방식이었다.
이건 사실 예전부터 언젠가 손봐야지 하고 미뤄둔 부분이었다. 기존 배포는 .env.prod를 .env로 바꾼 뒤 Docker image를 만드는 방식이었다. 운영 환경변수와 시크릿이 이미지에 함께 들어갔고, 지금까지는 그 방식으로 운영해왔다.
그래서 이 부분은 따로 선택지를 길게 비교하지 않았다. CDK로 옮기는 김에 끊고 가는 게 맞다고 봤다. 그래서 운영 환경변수와 시크릿을 SSM Parameter Store나 Secrets Manager로 옮기고, ECS task definition에서 runtime에 주입한다.
CDK에서는 environment와 secret을 분리해서 아래처럼 표현할 수 있다.
taskImageOptions: {
environment: {
NODE_ENV: "production",
SENTRY_RELEASE: imageTag,
},
secrets: {
DATABASE_URL: ecs.Secret.fromSecretsManager(databaseUrlSecret),
REDIS_URL: ecs.Secret.fromSsmParameter(redisUrlParameter),
},
}이 방식은 조금 귀찮다. 기존 .env.prod에 있던 값을 분류해야 한다. 비밀값인지, 일반 설정인지, 빌드 타임에 필요한 값인지, 런타임에 필요한 값인지 나눠야 한다. IAM task role도 해당 parameter나 secret을 읽을 수 있게 맞춰야 한다.
보안 체크리스트
이 선택만으로 자동으로 안전해지지는 않는다. 최소한 네 가지는 확인해야 했다.
- Docker image 안에
.env가 들어가지 않는가 - ECS task role이 필요한 SSM path만 읽을 수 있는가
- GitHub Actions user가 필요한 CDK bootstrap role만 assume하는가
- 배포 로그, shell history, dry-run 출력에 secret 값이 찍히지 않는가
시크릿 이관은 값을 어디론가 숨기는 작업에서 끝나지 않는다. 값이 이동하고 노출되는 경로를 줄여야 한다.
다섯 번째: SSM parameter는 스크립트로 한 번 옮기기
환경변수와 시크릿을 SSM Parameter Store로 옮기기로 했으니, .env.prod에 있던 값을 실제 parameter로 올려야 했다. 이건 큰 방향을 바꾸는 선택이라기보다 실행 방식의 문제였다.
수동으로 하나씩 넣을 수도 있었지만, 운영 값에서 오타나 누락이 나면 귀찮아진다. 그래서 .env.prod를 읽어서 /example/prod/backend/<KEY> 형태의 SecureString으로 올리는 one-off script를 만들었다.
먼저 dry-run으로 parameter 이름만 확인했다. 그다음 한 번 승인하고 SSM에 올렸다. 이렇게 하면 parameter 이름과 값이 SSM에 올라가는 과정에서 오타나 누락이 나면 바로 알 수 있다. 그리고 parameter가 올라간 뒤에는 CDK에서 해당 parameter를 참조하도록 task definition을 업데이트할 수 있다.
여섯 번째: ECR repository를 import할까, 새로 만들까
여기까지 오니 image repository도 다시 봐야 했다.
기존 운영 이미지는 example/app ECR repository에 있었다. 가장 단순한 길은 CDK에서 기존 repo를 import해서 계속 쓰는 방식이다. 그러면 image pre-copy도 필요 없고, 기존 digest와 tag 사용 방식을 그대로 가져갈 수 있다.
기존 repo 이름과 policy를 계속 유지할 수도 있었다. 반대로 CDK로 옮기는 김에 backend용 repo를 새로 만들고, 이후 배포는 그 repo를 기준으로 가져갈 수도 있었다.
나는 새 CDK baseline repo를 만드는 쪽을 골랐다.
기존 example/app을 import하면 현재 image와 tag 사용 방식을 그대로 가져갈 수 있다. 하지만 repo 이름과 policy의 소유 경계도 그대로 남는다. CDK로 옮기는 김에 backend용 repo를 따로 만들면 첫 image push 전까지 repo가 비어 있다는 점은 감수해야 하지만, repo 이름과 policy, retain 설정을 CDK 안에서 분명하게 잡을 수 있다.
여기서 baseline이라고 부른 이유는 ECS service가 올라가기 전에 필요한 기반 리소스이기 때문이다. ECR repo는 애플리케이션 stack이 image를 참조하기 전에 있어야 한다. 그래서 backend service stack과 별도로 baseline stack을 만들고, 그 안에서 example/backend repository를 생성하도록 했다.
이 선택으로 앞으로 CDK 배포 경로가 사용할 기준 repo를 명시적으로 둘 수 있었다. 기존 repo 이름을 계속 끌고 가지 않아도 됐다.
여기까지의 선택을 짧게 정리하면 이렇다.
| 결정 | 선택한 방향 | 이유 |
|---|---|---|
| Copilot 리소스 이관 방식 | 새 CDK stack 병렬 생성 | 기존 경로를 살려둔 채 새 경로를 검증하고, 문제가 생기면 되돌리기 쉽다 |
| 네트워크 | 기존 VPC/subnet 사용 | DB, Valkey, SQS, Lambda 같은 기존 네트워크 조건을 크게 흔들지 않는다 |
| Service Connect | 이번 범위에서 제외 | 내부 서비스 디스커버리 의존성이 없어 마이그레이션 변수에서 뺐다 |
| 환경변수와 시크릿 | SSM/Secrets Manager runtime 주입 | 운영 secret이 Docker image에 들어가지 않게 한다 |
| ECR repository | 새 backend repo 생성 | 새 CDK 배포 경로가 사용할 image repository를 명확히 둔다 |
실행 순서와 실제 결과
작업 순서 개요
여기까지 정하고 나니 실제 작업 순서는 꽤 단순해졌다.
먼저 CDK deploy 전에 확인할 것들을 정리했다.
- 사용할 image tag 결정. 현재는
latest또는 특정 git SHA tag - 현재 AWS user가
cdk deploy에 필요한 권한을 갖고 있는지 확인 - default qualifier
hnb659fds로cdk bootstrap이 1회 실행되어 있는지 확인 github-actionsuser가 필요한 CDK bootstrap role들을 assume할 수 있는지 확인
그다음 cdk diff를 먼저 본다.
- 새로 만들 리소스가 ECS cluster, service, ALB, security group, log group, IAM 정도인지 확인
- 기존 Copilot stack을 건드리지 않는지 확인
diff가 납득되면 병렬 CDK stack을 deploy한다.
- 기존 VPC/subnet 사용
- 새 ALB 생성
- Service Connect off
- SSM runtime secret 주입
배포 후에는 새 ALB DNS로 직접 검증한다.
/health- 주요 API smoke test
- CloudWatch logs
- ECS task start 실패 여부
- S3/SQS 접근 여부
그다음 image repository 경로를 정리한다.
- 새 baseline stack으로
example/backendECR repo 생성 - ECR repo policy와
Retain설정 확인 - prod workflow의 push 대상을
example/backend로 변경 - 첫 image push는 GitHub Actions workflow에서 수행
마지막으로 GitHub Actions를 교체한다.
- Docker build에서
.env없이 image 생성 - ECR push
SENTRY_RELEASESSM 갱신cdk deploy -c imageTag=$GITHUB_SHA
이 순서에서 가장 중요하게 본 것은 기존 경로를 건드리지 않는 일이었다. 새 리소스를 먼저 만들고, 새 ALB로 검증한 뒤, 마지막에 배포 파이프라인을 갈아끼운다.

CDK bootstrap을 먼저 한다
여기서 하나 더 확인해야 할 것이 있었다.
cdk deploy를 하려면 대상 AWS account와 region이 먼저 bootstrap되어 있어야 한다. AWS CDK 문서에 따르면 bootstrapping은 CDK가 배포에 사용할 AWS 환경을 준비하는 과정이다. 이때 CDK는 asset을 올릴 S3 bucket, Docker image를 위한 ECR repository, 배포와 lookup과 publishing에 필요한 IAM role들을 만든다.
추천은 default qualifier인 hnb659fds로 cdk bootstrap을 한 번 실행하는 방식이다. 괜히 custom qualifier를 쓰면 bootstrap role ARN, asset bucket 이름, GitHub Actions assume role 정책까지 전부 커스텀 이름을 따라가야 한다. 특별한 조직 표준이 없다면 CDK 기본값을 쓰는 편이 더 단순하다.
실행 단계는 이렇다.
cd infra/cdk
yarn cdk bootstrap aws://<AWS_ACCOUNT_ID>/ap-northeast-2다만 이 명령은 IAM role과 S3 bucket, ECR repository 같은 리소스를 새로 만든다. 보안성 있는 변경이므로 cdk diff 이전에 한 번 실행하되, 어떤 role이 생기는지 알고 있어야 한다.
bootstrap 이후에는 GitHub Actions에서 쓰는 github-actions user의 sts:AssumeRole policy에 CDK bootstrap role ARN들을 추가해야 한다. 그래야 GitHub Actions가 장기 권한을 직접 들고 배포하지 않고, CDK가 만든 deployment role, lookup role, file publishing role 같은 정상 경로를 assume해서 배포할 수 있다.
bootstrap 이후 권한을 좁게 열기
bootstrap이 끝난 뒤에는 GitHub Actions 권한을 정리했다. 기존 github-actions user가 모든 것을 직접 들고 배포하게 두기보다, CDK bootstrap이 만든 role을 assume하는 쪽이 맞았다.
다만 여기서도 권한을 넓게 열고 싶지는 않았다. 기존 example-* assume 권한은 유지하되, CDK CLI가 직접 사용하는 deploy, lookup, file publishing, image publishing role만 추가했다. CloudFormation execution role은 CloudFormation이 쓰는 role이라 GitHub Actions user가 직접 assume할 대상에서 뺐다.
정책을 업데이트한 뒤에는 cdk diff를 다시 실행했다. 이때부터 CDK가 bootstrap role을 사용해 template publish와 read-only change set 기반 diff까지 성공했다. 배포 권한 경로가 정상적으로 열린 것이다.
마지막으로 image tag도 확인했다. 첫 병렬 배포에서는 운영과 같은 이미지를 띄우는 게 중요했기 때문에, latest가 현재 운영 task의 digest와 같은지 봤다. 확인 결과 digest가 일치했고, 첫 CDK 배포는 imageTag=latest로 진행해도 된다고 판단했다.
병렬 stack 배포 결과
여기까지 확인한 뒤 실제로 cdk deploy를 실행했다.
배포는 기존 Copilot stack을 건드리지 않고 새 CDK stack을 병렬로 띄우는 방식으로 진행했다. 새 ECS service와 ALB가 생성됐고, 새 ALB DNS로 직접 /health를 호출했을 때 HTTP 200 OK가 돌아왔다. 응답의 NODE_ENV도 prod였다.
이 정도면 새 서비스가 실제 트래픽을 받을 최소 조건은 만족했다고 봤다. 아직 도메인 전환이나 GitHub Actions 완전 교체 전이었지만, 기존 경로를 살려둔 상태에서 CDK 기반 경로가 따로 살아 있는 것까지 확인한 셈이다.
수동 CDK 배포 workflow 추가
새 병렬 stack이 살아 있는 것을 확인한 뒤에는 GitHub Actions 쪽을 정리했다.
진행한 내용은 이렇다.
- 새 수동 배포 workflow 추가:
.github/workflows/cd-backend-prod-cdk.yml - CDK README에 운영 절차 갱신:
infra/cdk/README.md - workflow는
workflow_dispatch전용으로 구성 - 기존 Copilot prod workflow는 아직 건드리지 않음
여기서 중요한 결정은 image tag 처리였다.
처음에는 latest를 바로 갱신하는 방식도 생각할 수 있다. 하지만 이러면 DB migration이나 CDK deploy, 새 ALB health check 중간에 실패했을 때 latest가 이미 새 이미지를 가리키게 된다. 기존 Copilot 서비스가 여전히 latest를 기준으로 움직이고 있다면, 이건 불필요한 위험이다.
그래서 새 CDK workflow에서는 Docker image를 먼저 $GITHUB_SHA tag로만 push하게 했다. 그 다음 DB migration, CDK deploy, /health 검증이 모두 성공한 뒤에만 같은 digest를 latest로 승격한다.
실행 순서는 이렇게 잡았다.
1. build image
2. push $GITHUB_SHA
3. run DB migration
4. cdk deploy -c imageTag=$GITHUB_SHA
5. check /health
6. promote the same digest to latest이 방식은 조금 더 번거롭다. 하지만 실패 지점이 생겼을 때 latest가 오염되지 않는다. 새 CDK 경로 검증이 끝나기 전까지 기존 Copilot prod workflow와 기존 서비스는 그대로 둔다. 배포 파이프라인도 인프라처럼 병렬로 붙인 셈이다.
새 배포 경로는 만들되, 기존 prod 경로는 아직 건드리지 않는다. latest는 성공이 확인된 뒤에만 움직인다.
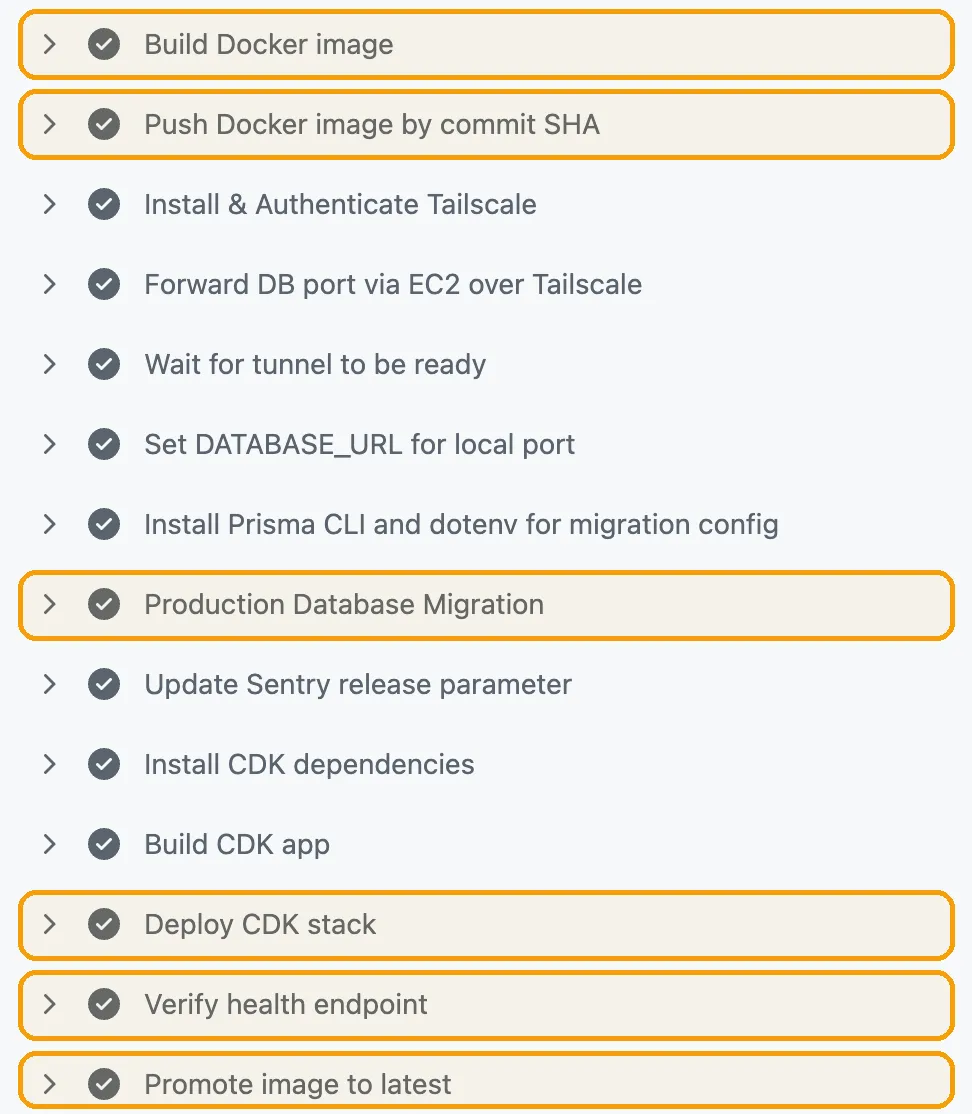
수동 workflow 실행 결과
이후 수동 배포 workflow를 실제로 한 번 돌렸다. 결과는 성공이었다.
중요한 건 GitHub Actions의 초록 체크 자체보다 tag가 의도대로 붙고 승격됐는지였다. workflow는 먼저 commit SHA tag로 이미지를 push했고, 그 이미지로 CDK deploy와 /health 검증까지 마친 뒤에야 같은 digest를 latest로 승격했다.
이 시점부터 새 CDK 경로는 GitHub Actions로 재현 가능한 배포 경로가 됐다.
ECR baseline stack 생성
그다음에는 backend image repository도 정리했다. 기존 example/app을 그대로 끌고 올 수도 있었지만, 새 배포 경로를 Copilot 흔적과 분리하고 싶었다.
그래서 CDK가 소유하는 ECR repository를 example/backend로 새로 만들고, prod CDK workflow의 push 대상도 그쪽으로 바꿨다. 이후 workflow는 example/backend:$GITHUB_SHA를 먼저 push하고, 그 image tag로 CDK deploy를 실행한다.
처음에는 새 repo가 비어 있었다. 그래서 이 변경은 main에 반영한 뒤 수동 CDK workflow를 한 번 돌려서, 새 repo 기반 배포가 실제로 되는지 확인하기로 했다.
전환과 정리
수동 GitHub Actions workflow까지 성공하고 나면, 다음 일은 실제 트래픽을 어디로 보낼지 바꾸는 작업이다.
여기서부터는 운영 절차가 더 중요해진다. DNS, TLS 인증서, ALB health, ECS rollout, 앱 오류율, rollback 시간이 전부 같이 걸린다. 새 CDK stack이 정상이어도 곧바로 고객 트래픽을 넘겨도 된다는 보장은 없다.
DNS cutover 전에 rollback부터 정리하기
운영 API 도메인은 Cloudflare DNS에서 CNAME으로 관리되고 있었다. 그래서 어떤 CNAME record를 기존 ALB에서 새 ALB로 바꾸고, 문제가 생기면 무엇을 어디로 되돌릴지 정하면 됐다.
여기서는 예시로 운영 API 도메인을 api.example.com이라고 두겠다.
바꾸는 값은 단순했다.
Before:
사용자/앱 -> api.example.com -> 기존 Copilot ALB -> 기존 Copilot ECS service
After:
사용자/앱 -> api.example.com -> 새 CDK ALB -> example-prod-app-cdk ECS service그래서 cutover 전에 다음을 정리했다.
- 실제 운영 API 도메인
- 현재 record가 가리키는 기존 Copilot ALB
- 새 CDK ALB가 같은 HTTPS 조건을 만족하는지
- cutover 전 TTL을 낮출지
Cloudflare CNAME을 새 ALB로 넘기기
실제로는 api.example.com의 CNAME을 기존 Copilot ALB에서 새 CDK ALB로 바꿨다.
Before:
api.example.com -> <old-copilot-alb>.ap-northeast-2.elb.amazonaws.com
After:
api.example.com -> <new-cdk-alb>.ap-northeast-2.elb.amazonaws.com변경 후에는 DNS가 새 CDK ALB를 가리키는 것까지 확인했다. 여기까지가 인프라 레벨의 cutover였다.
그런데 여기서 끝나지 않았다. DNS와 ALB가 정상이어도 앱이 DB나 cache에 붙지 못하면 사용자 입장에서는 장애다. 실제로 cutover 직후에는 RDS 쪽 연결 timeout이 먼저 눈에 띄었다.
RDS와 Valkey security group 수정
처음에는 RDS 네트워크 연결을 의심했다. 실제로 RDS security group이 문제였고, Valkey도 같은 이유로 막혀 있었다.
원인은 단순했다. DNS와 ALB는 새 CDK 쪽을 잘 보고 있었지만, 새 ECS task의 security group이 RDS와 Valkey security group에 허용되어 있지 않았다. 기존 Copilot ECS security group만 허용된 상태였으니, 앱 입장에서는 DB/cache timeout처럼 보일 수밖에 없었다.
RDS security group에는 새 CDK ECS security group을 TCP 5432 source로 추가했고, Valkey security group에는 같은 security group을 TCP 6379 source로 추가했다. 그 뒤 ECS service를 한 번 강제 재배포했다.
수정 후에는 ECS service가 steady state로 돌아왔고, ALB target도 healthy가 됐다. https://api.example.com/health도 OK였다. 로그에서는 Valkey unreachable이 사라졌고, Prisma도 timeout 대신 실제 DB 응답을 받기 시작했다.
이번 마이그레이션에서 꽤 좋은 reminder였다. VPC를 그대로 써도 security group 관계는 따로 봐야 한다. 새 ECS service는 새 security group을 갖고 있고, RDS나 Valkey 입장에서는 그 SG가 “새로운 호출자”다.
기존 Copilot service는 바로 지우지 않기
DNS cutover가 끝나고 새 CDK service가 정상으로 보여도, 기존 Copilot ECS service를 바로 지우지는 않았다.
이때 기존 Copilot cluster와 service는 운영 도메인의 주 경로에서 빠진 상태였다. api.example.com은 새 CDK ALB를 보고 있었고, 기존 Copilot service는 old Copilot ALB에 붙어 있었다. 그래도 old Copilot service는 rollback 대기용으로 남겨두는 편이 나았다.
이 시점의 질문은 “언제 삭제할까”였다. 운영 도메인은 이미 새 CDK ALB를 보고 있었지만, 방금 RDS/Valkey security group 누락을 고친 직후였다. 새 경로가 한 번 정상으로 돌아왔다고 해서 바로 마지막 되돌림 경로까지 없애고 싶지는 않았다.
그래서 cutover 직후에는 old Copilot ECS service를 rollback target으로 잠시 유지했다. 새 경로가 안정적으로 보인 뒤에야 desired count를 0으로 낮췄다.
이렇게 하면 비용은 줄일 수 있지만, rollback은 조금 길어진다. 문제가 생기면 old service를 다시 올리고 target health를 확인한 뒤, Cloudflare CNAME을 기존 Copilot ALB로 되돌려야 한다.
old Copilot stack 삭제 범위 정하기
desired count를 0으로 낮춘 다음날, 바로 삭제하지 않고 상태를 다시 확인했다.
삭제 기준은 길게 잡지 않았다.
- 운영 도메인이 새 CDK ALB를 보고 있는가
- old Copilot ECS service와 target group이 비어 있는가
- 새 CDK service와 target이 healthy 상태인가
- rollback이나 장애 분석에 필요한 ECR repository, log, secret, ACM certificate가 따로 남아 있는가
이 조건을 보고 Copilot app service stack과 old ECS service 리소스부터 삭제 대상으로 봤다. 다만 Copilot env stack 전체는 보류했다. 기존 Copilot example-prod stack이 아직 네트워크 리소스를 소유하고 있었기 때문이다. old ECS service가 더 이상 트래픽을 받지 않더라도, env stack을 지우면 VPC/subnet/route/security group 같은 공유 기반 리소스가 같이 삭제 대상이 될 수 있었다.
순서는 자연스럽게 정해졌다. 서비스부터 줄이고, 네트워크 소유권을 정리하고, 마지막에 env stack 잔여물을 본다.
network baseline stack으로 소유권 이동
이 지점에서 다시 네트워크 소유권 문제가 나왔다.
초기에 CDK backend stack은 기존 VPC를 “참조”만 했다. 기존 VPC와 subnet을 사용하지만, CDK가 그 리소스를 소유하지는 않았다. Copilot example-prod stack을 지우면 그 stack이 소유한 VPC와 subnet까지 삭제 대상이 될 수 있었다. 이 상태에서는 Copilot env stack을 자신 있게 지우기 어려웠다.
새 VPC를 따로 만들면 RDS/Valkey, route, security group을 다시 검증해야 했다. 그래서 기존 VPC/subnet/route/security group은 그대로 두고, CloudFormation 소유권만 Copilot env stack에서 CDK network baseline stack으로 옮겼다.
네트워크 소유권을 넘기고 나니 Copilot env stack에는 IAM roles, old ECS cluster, service discovery namespace, log policy 같은 잔여 리소스만 남았다.

여기까지 하고 나서 달라진 것
CDK 경로를 만들었다고 서버가 갑자기 빨라지지는 않았다.
유저 입장에서는 아무 일도 없어야 한다. 사실 그게 좋은 마이그레이션인 것 같다.
운영하는 입장에서는 꽤 달라졌다.
인프라 변경이 코드 리뷰 대상이 됐다. cdk diff로 변경 범위를 먼저 보고 배포할 수 있게 됐다. Copilot의 manifest.yml도 충분히 읽기 쉬웠지만, 지원 종료 이후에도 계속 유지할 수 있는 IaC 경로가 생겼다는 점이 달랐다.
물론 CDK에도 비용은 있다.
CDK를 쓰면 AWS 리소스를 더 많이 알아야 한다. Copilot이 대신 골라주던 선택지를 내가 직접 골라야 한다. VPC를 어떻게 다룰지, ALB를 public으로 둘지, egress 경로를 어떻게 맞출지, autoscaling 기준을 무엇으로 할지 같은 질문들이다.
그래도 이번에는 그 비용을 감수하는 쪽이 맞았다고 본다.
정리
잘 쓰던 배포 도구가 지원 종료되면서, 운영을 계속할 수 있는 다른 경로를 만들게 되었다.
솔직히 마이그레이션을 끝내고 나서도 Copilot manifest가 편하긴 했다는 생각은 그대로 남아 있다. CDK는 더 많은 AWS 세부사항을 직접 봐야 하기 때문이다. 대신 이제는 필요한 리소스를 코드로 설명할 수 있다.
그래서 결론도 단순하다. 지원 종료가 곧 장애는 아니지만, 프로덕션 배포 경로라면 언젠가는 정리해야 한다고 봤다. 이번에는 그 시점이 Copilot CLI 지원 종료일 직전이었다.
Share this post
Keep reading
Related posts
More posts
Comments