fork()는 언제 완료되는가 — PintOS fork/wait 세마포어 위치 찾기
크래프톤정글 PintOS 프로젝트에서 fork()와 wait() 시스템 콜을 구현하며 부모와 자식 프로세스의 동기화 지점을 어떻게 찾아갔는지 정리합니다.

On this page
들어가며
PintOS 시스템 콜 구현 프로젝트에서 fork()와 wait()를 구현하며 고민했던 부분은 sema_down()과 sema_up()을 어디에 둘 것인가가 문제였다.
fork()는 부모 프로세스를 복사해 자식 프로세스를 만드는 시스템 콜이다. wait()은 부모 프로세스가 자식 프로세스가 끝날 때까지 기다렸다가 그 자식의 종료 상태를 받아오는 시스템 콜이다. 이를 구현하기 위해 부모와 자식을 동기화할 수 있는 장치가 필요하며 PintOS에서는 세마포어로 구현한다.
단순하게 말하면 부모 프로세스는 자식을 만들고, 자식 프로세스는 자기 일을 마친 뒤 부모를 깨우면 된다. 말은 쉬운데 막상 syscall_handler -> fork -> process_fork -> do_fork -> load 식으로 점점 저수준 호출을 따라가다 보면 저 단순한 설명으로 구현을 완성시키기에는 부족하다는 걸 알게 된다!
자식 스레드가 생성되면 충분한가? 자식의 tid가 생기면 충분한가? page table이 복사된 다음? 아니면 가상 메모리와 file descriptor table까지 다 복사된 다음? …
구현하며 정답을 찾아갔던 과정을 간단해 포스팅해보고자 한다.
스레드 생성은 fork 완료가 아니다
fork()에서 부모가 최종적으로 받아야 하는 값은 자식의 tid다. 그래서 처음에는 thread_create()가 성공하고 tid를 받으면 부모가 바로 fork()를 끝내도 될 것 같이 보인다.
하지만 tid를 받았다는 사실은 자식 스레드가 만들어졌다는 뜻이지, fork()의 결과로 자식 프로세스가 실행 가능한 상태에 도달했다는 뜻은 아니다.
fork() 구현에서는 자식 스레드가 만들어진 뒤에도 해야 할 일이 남아 있다. 부모의 실행 컨텍스트를 넘겨받고, 주소 공간을 준비하고, VM 정보를 복사하고, file descriptor table도 맞춰야 한다. 이 작업이 끝나기 전에 부모가 fork()를 성공으로 반환하면 부모 입장에서는 자식이 만들어졌다고 믿지만, 자식 쪽 초기화는 아직 끝나지 않은 상태가 된다.
반드시 자식 프로세스의 pid를 리턴이라는 Gitbook 내용만 보고 프로세스 아이디가 생겼으니 반환하고 끝내면 되겠네!! 하면 안된다… 지금 생성 된 tid는 fork의 완료 신호가 아니라 fork 작업을 시작할 자식 스레드를 가리키는 식별자 역할이라고 보면 된다.
fork에서 검토한 가설
내가 고민했던 후보는 대략 이런 순서였다.
| 후보 | 설명 |
|---|---|
| 자식 스레드 생성 직후 | 스레드가 만들어졌을 뿐, fork에 필요한 자원 복사는 끝나지 않았다. |
자식 tid 확보 직후 | 식별자가 생겼다고 해서 자식의 실행 상태가 완성됐다고 볼 수 없다. |
| page table 복사 직후 | 가상 메모리와 file descriptor table 복사가 남아 있다. |
| VM 복사 직후 | 메모리 상태는 맞춰졌지만 열린 파일 상태가 아직 부모와 일치하지 않을 수 있다. |
| file descriptor table 복사 이후 | 부모가 fork() 성공을 믿고 다음 줄로 넘어가도 되는 기준에 가장 가깝다! |
이 표만 보면 답이 명확해 보이지만, 익숙치도 않은 C언어로 작성된 OS의 여러 함수들을 따라가다보면… 모든 지점이 다 완료된 것 같고 그럴싸해보여서 문제였다. 🫨
그래서 먼저 호출 관계를 그렸다. fork()가 어디서 자식 스레드를 만들고, do_fork()가 어디서 부모의 상태를 복사하고 실패했을 때 어떤 경로로 빠지는지 확인했다. 그다음 가능한 동기화 지점 가설을 몇 개 세우고 실제 코드에 넣어보며 테스트했다.

그 결론은 다음과 같다.
일단 부모는 자식 스레드를 만든 뒤 tid를 받는다. 하지만 바로 반환하지 않는다. 자식이 fork 초기화를 끝냈다는 신호를 줄 때까지 sema_down()으로 기다린다.(= block 상태)
자식은 do_fork() 안에서 필요한 복사를 마친다. page table, VM, file descriptor table 복사가 끝나고 나서야 부모를 깨운다. 이때 sema_up()을 호출한다. 그러면 부모는 비로소 fork()의 반환값으로 child tid를 돌려줌으로써 fork 시스템 콜 호출이 끝난다.
중요한 것은 부모는 단순히 자식 스레드 생성만을 기다리는 게 아니라, child가 fork의 결과로 실행 가능한 상태에 도달했는지를 기다린다는 점이었다. tid가 생겼다고 해서 fork가 끝났다고 믿으면 안 된다. 부모가 fork()를 성공으로 반환하기 전에 자식이 필요한 초기화를 모두 마쳤다는 사실을 보장해야 한다.
wait에서 검토한 가설
wait()에서도 semaphore를 써야 했으나 fork와는 조금 다르다.
fork()의 핵심은 “자식이 준비됐는가”라면 wait()의 핵심은 “부모가 자식의 종료를 관찰해도 되는가”이다. 이게 무슨 말이냐면…
wait(pid)가 호출되면 부모는 해당 자식이 종료될 때까지 기다려야 한다. 자식이 끝나면 부모는 자식의 exit status를 받아야 한다. 실패한 경우에는 -1을 반환해야 한다.
여기서도 sema_down()과 sema_up()의 위치가 애매했다. 부모는 process_wait()에서 기다리면 된다. 문제는 자식이 process_exit()의 어느 지점에서 부모를 깨워야 하는가였다.
프로세스 메모리를 모두 해제하고? (No, 그 바로 전) 열린 파일을 모두 닫고 나서? (No, 그 다음)
역시 냅다 코드만 읽어서는 전부 그럴싸해보여서 호출 관계를 정리하고 가능한 동기화 지점 가설을 몇 개 세우고 실제 코드에 넣어보며 테스트했다.
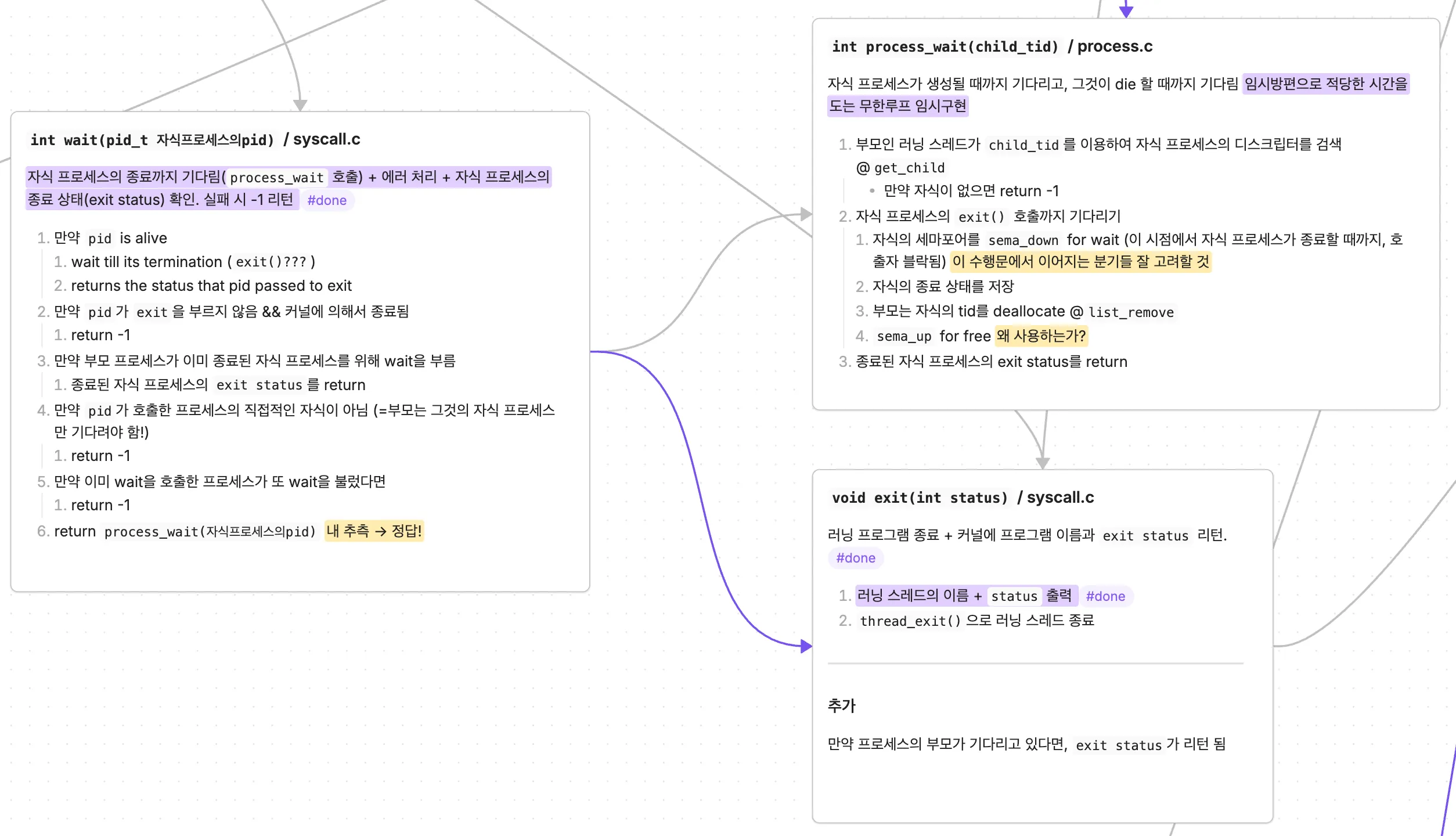
처음에는 자식의 메모리를 모두 해제한 뒤 부모를 깨우는 경우를 생각해봤다. 하지만 부모가 읽어야 하는 종료 상태나 parent-child 관계 정보가 이미 사라지면 안 된다. 반대로 너무 이른 시점에 부모를 깨우면 자식이 아직 종료 처리를 마치지 않았는데 부모가 wait을 끝낼 수 있다.
결론적으로 내 구현에서는 부모 프로세스는 wait이 호출되면 일단 세마를 감소시키고 대기상태에 빠진다. 그리고 자식이 열린 파일을 닫고 file descriptor table을 정리한 뒤 부모를 깨웠다. 그 다음 자식의 가상 메모리와 page table 메모리를 정리했다.
여기서 중요한 건 부모가 읽어야 하는 상태는 부모가 읽을 수 있는 곳에 남아 있어야 하고, 자식만 쓰는 자원은 그 이후 정리되어도 된다는 점이다. wait()의 semaphore는 “자식이 종료됐다”는 사건뿐만 아니라 “부모가 읽어야 할 종료 정보가 준비됐다”는 사실까지 보장해야 한다.
나만의 Takeaway
fork()와 wait()에서 세마포어 위치 정하기는 결국 각 시스템 콜의 완료 조건을 무엇으로 볼 것인지의 문제였다고 할 수 있는데,
OS 시간에 배운 개념적인 내용은 사실 꽤 간단하다고 느껴질 수 있지만, 구현 레벨에서는 그보다 더 디테일하게 파고 들어야 하고 그럴싸한 지점마다 “왜 안 되지?”를 고민해야했다.
나만의 해결책은 호출 다이어그램 그리고, 가능한 동기화 지점 가설을 세우고, 실제 코드에 넣어보며 테스트하기였다. 막상 정답을 찾고 보면 또 당연해보이는 것은 왜일까?
Share this post
Keep reading

More posts
Comments